Análisis de datos
Irving Omar Morales Agiss

¿Qué es análisis de datos?
Análisis de datos es:
Preguntar
Interrogar
Entrevistar
... a bases de datos ...
Entrevistar a los datos
Directo al grano ...

... ya conozco la pregunta.
Entrevistar a los datos
Directo al grano ...

... ya conozco la pregunta.
Entrevistar a los datos
Suavecito ...

... dejo que los datos me guíen.
Entrevistar a los datos
Suavecito ...
... dejo que los datos me guíen.
Regla #1
Si torturas lo suficiente a los datos, confesarán
¿Qué buscamos en los datos?
- Respuestas a preguntas ya establecidas
- Patrones que corroboren o descarten nuestras hipótesis
- Hallazgos importantes (outliers)
Regla #2
Todos los datos tienen sesgos
¿De dónde vienen los sesgos?
Los datos viven en bases de datos
- Proceso de planeación
- Proceso de medición
- Proceso de captura
- Proceso de edición
Todo esto es susceptible a sesgos
Y ni siquiera estamos considerando los posibles errores
- Incertidumbre
- Errores de medición
- Errores de captura
Regla #3
Los datos nunca están completos
Regla #4
En los datos encontramos patrones que existen y que no existen
¿De dónde vienen?
- Datos electorales
- Datos de dineros
- Datos deportivos
- Datos del espectáculo
- Datos de los hogares
- Datos de cultivos
- Datos de movilidad
- ¿ ... ?
¿Qué les preguntamos?
- Datos electorales
- Datos de dineros
- Datos deportivos
- Datos del espectáculo
- Datos de los hogares
- Datos de cultivos
- Datos de movilidad
- ¿ ... ?
¿Qué sesgos tienen?
- Datos electorales
- Datos de dineros
- Datos deportivos
- Datos del espectáculo
- Datos de los hogares
- Datos de cultivos
- Datos de movilidad
- ¿ ... ?
¿Qué patrones interesantes arrojan?
- Datos electorales
- Datos de dineros
- Datos deportivos
- Datos del espectáculo
- Datos de los hogares
- Datos de cultivos
- Datos de movilidad
- ¿ ... ?
gran parte del análisis es visual
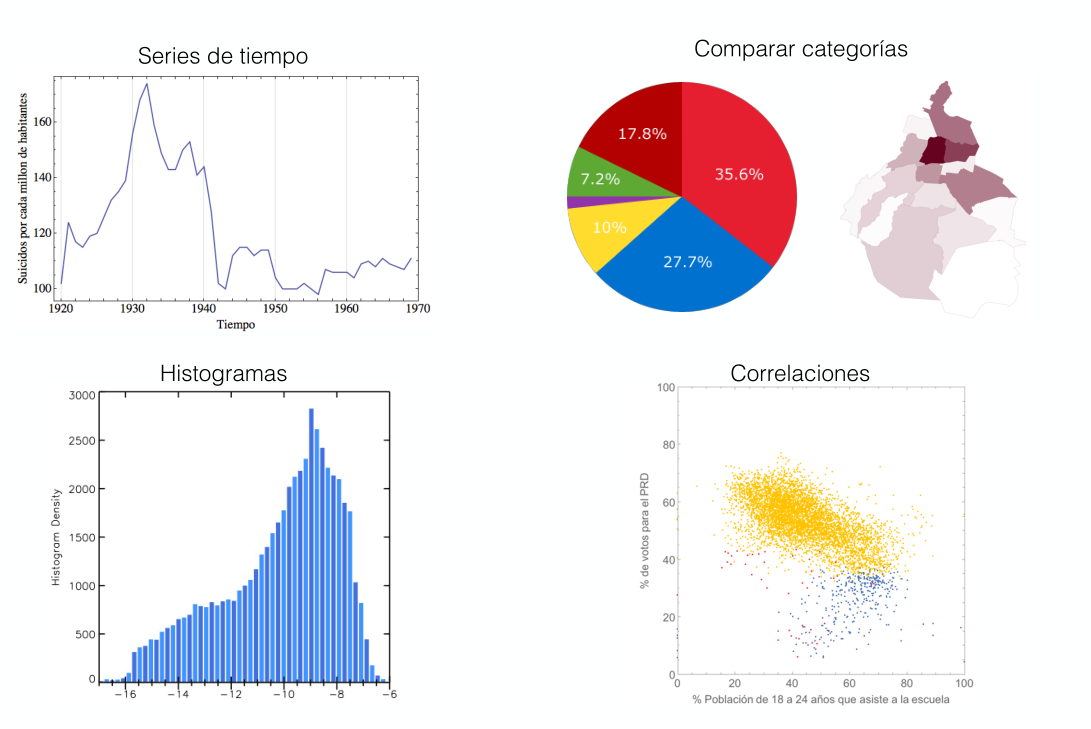
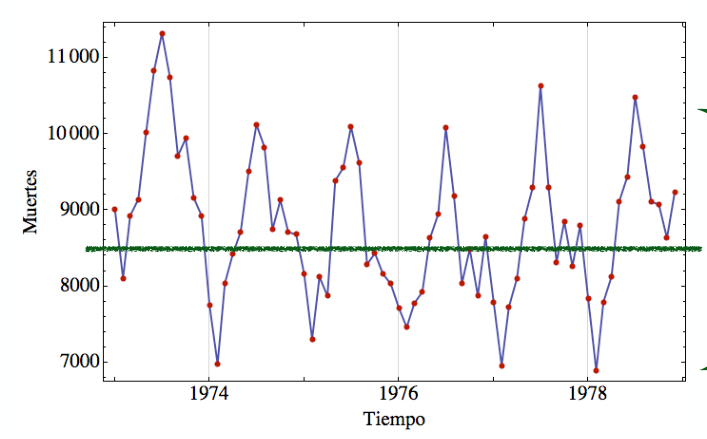
¿Cómo se hace una serie de tiempo?
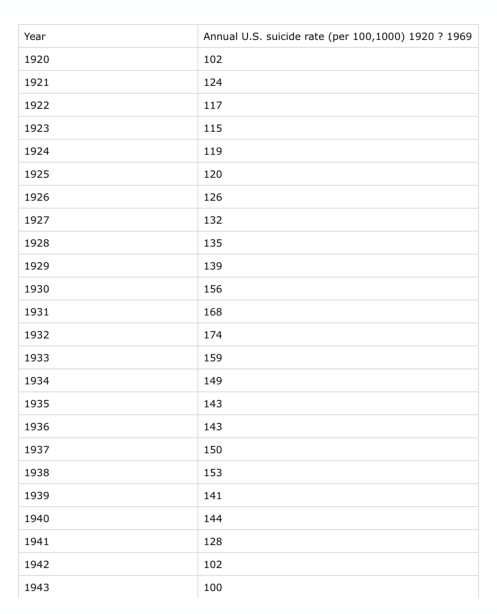
Necesitamos datos con una variable temporal, ordenarlos... y graficar
¿Qué patrones buscamos en las series de tiempo?
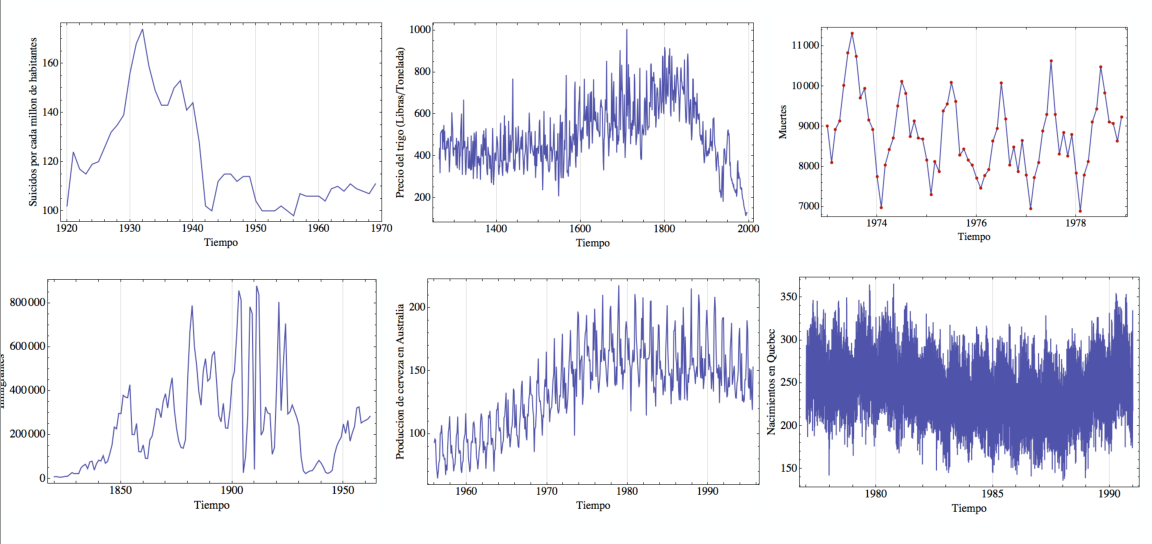
Tendencias, máximos, mínimos, valores extremos, periodicidades, el centro, la dispersión
¿Que es un histograma?
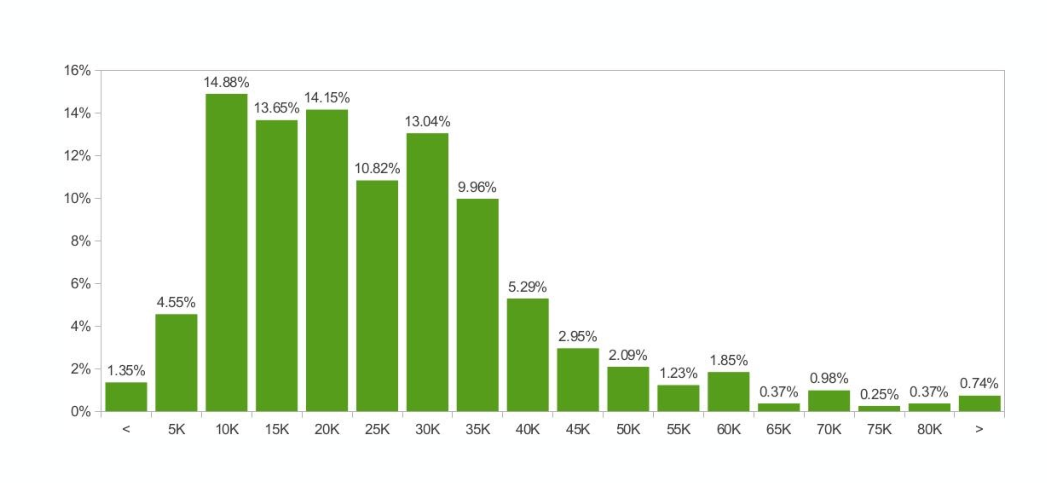
Un histograma cuenta cuantos elementos hay en cada categoría
¿Cómo se hace un histograma?
Inventamos categorías que tengan sentido y contamos
(A veces se presentan como porcentajes, o como probabilidades en vez de cuentas totales)
¿Qué buscamos en un histograma?
Máximos, mínimos, categorías extremas, el centro, la dispersión
¿Cual es el centro?
Un buen centro es el promedio, pero existen otros, la media, la moda
¿Cómo se calcula un promedio?
Se suman los datos y se divide entre el número de datos
(existen versiones más sofisticadas)
Cuidado con el promedio!

¿Cómo se calcula la mediana?
Se ordenan los valores y se selecciona el de en medio
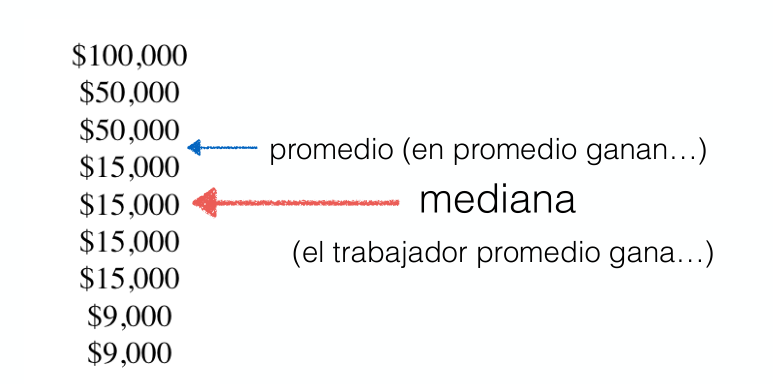
(si el número de datos es par se toman los dos de en medio y se promedian)
¿Cómo se calcula la moda?
Es el valor que aparece más veces
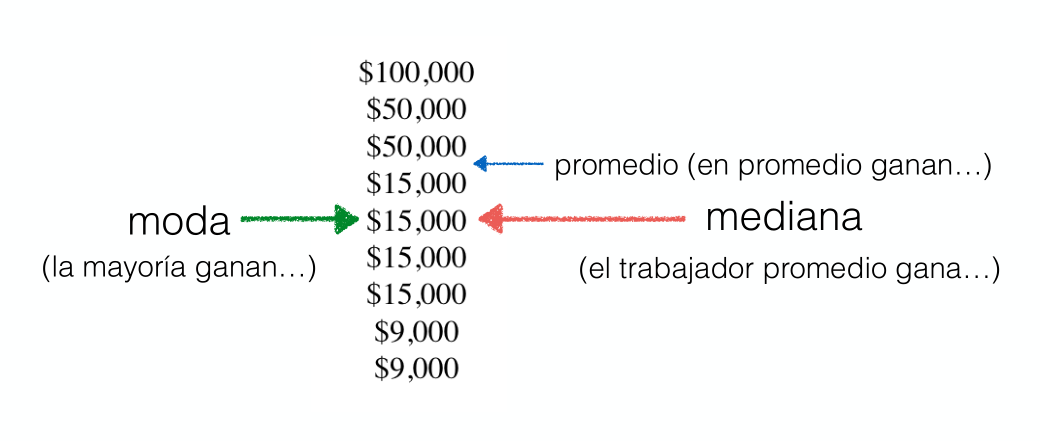
¿Qué hay de la dispersión?
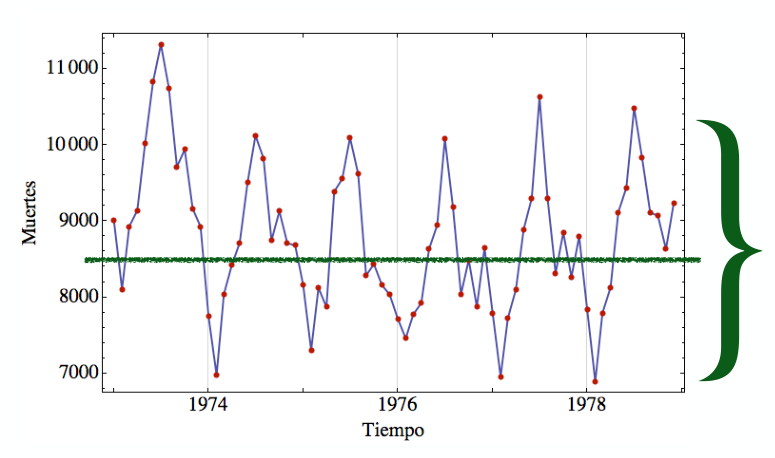
La dispersión nos dice que tan lejos del promedio hay valores
¿Cómo se calcula la dispersión?

Es más fácil con herramientas y código!
¿Cómo comparo distintas categorías?
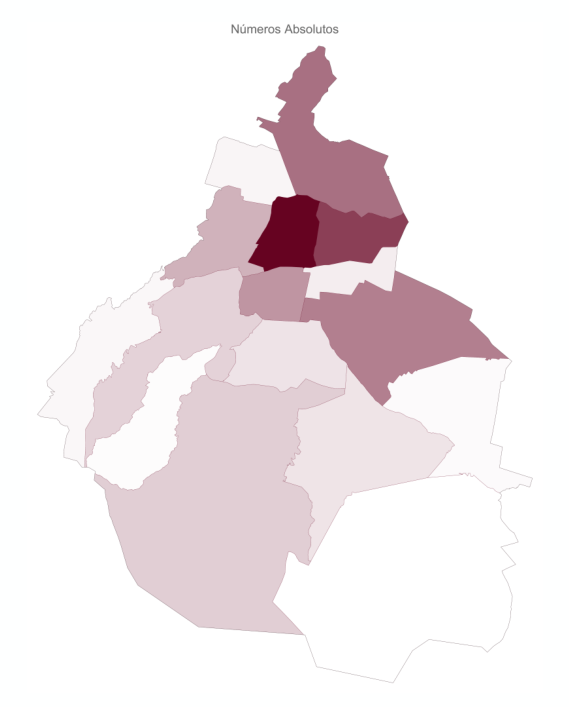
Hay que tener cuidado, hay más donde hay más personas
Necesitamos quitar el efecto de la población
Tenemos que usar números relativos (tasas) y no números absolutos
Necesitamos quitar el efecto de la población
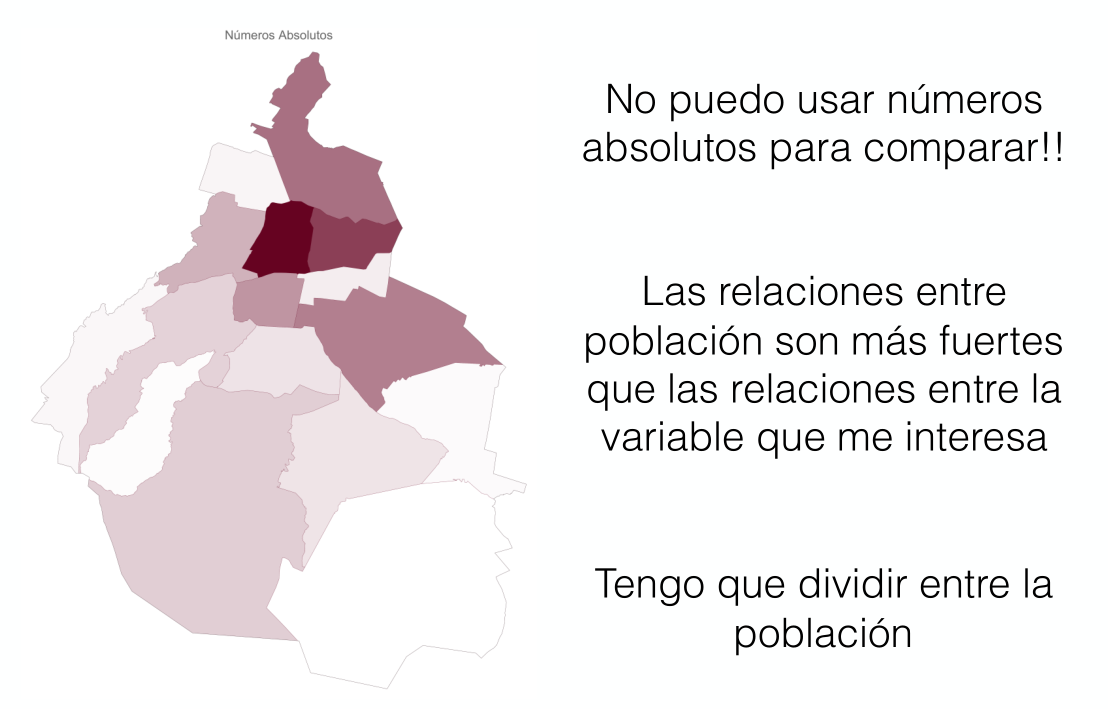
Necesitamos quitar el efecto de la población
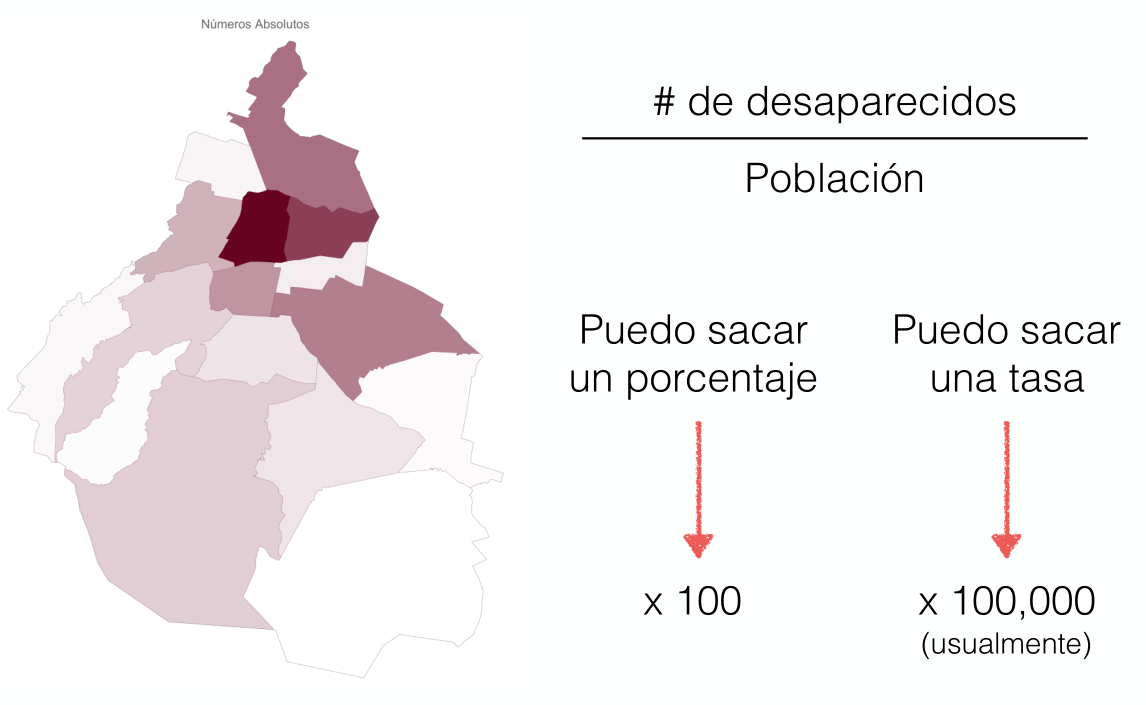
Existen patrones más complejos:

por ejemplo las correlaciones
Existen patrones más complejos:
cada punto es un elemento, graficamos los valores para dos variables
Existen patrones más complejos:
despues exploramos si se "mueven" de forma sistemática
Cuidado! Nunca asuman que una variable es debido a la otra
Correlación no implica causa! NUNCA!
Herramientas
Hojas de cálculo:




Herramientas
Lenguajes de programación:




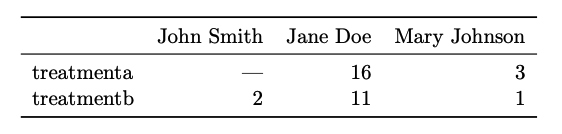
Una base de datos es un conjunto de valores,
- cuantitativos (números)
- cualitativos (texto, cadenas)
Cada valor pertenece a una variable y a una observación
- Una variable contiene todos los valores que miden una misma propiedad
- Una observación contiene todos los valores medidos para las propiedades de una misma unidad

El 80% del tiempo de análisis es limpiar y ordenar los datos
Estructurar los datos
No mezclar diferentes tipos de datos
Diferenciar entre números y texto
Estructurar los datos
Para datos faltantes NO usar cero
Dejar en blanco o usar algún otro valor
Estructurar los datos
No usar la hoja como un escritorio
Seguir la estructura de la hoja
Estructurar los datos
No usar colores para marcar cosas importantes
Crear variables para marcar cosas importantes
Estructurar los datos
No usar multicolumnas o multifilas
Tratar de hacer nuestros datos "Tidy" (ordenada)
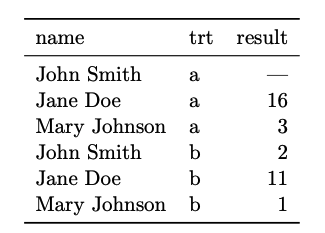
Una base de datos "Tidy" (ordenada)
- Cada variable está en una columna
- Cada observación está en una fila
- Cada tipo de observación está en una tabla
¿Cómo manejamos datos?
Instalamos python
La forma más fácil de instalar python es a través de anaconda
www.anaconda.com/distribution/
Descargamos e instalamos.
Depues de instalar, buscamos en nuestras aplicaciones una que se llame "Anaconda navigator"
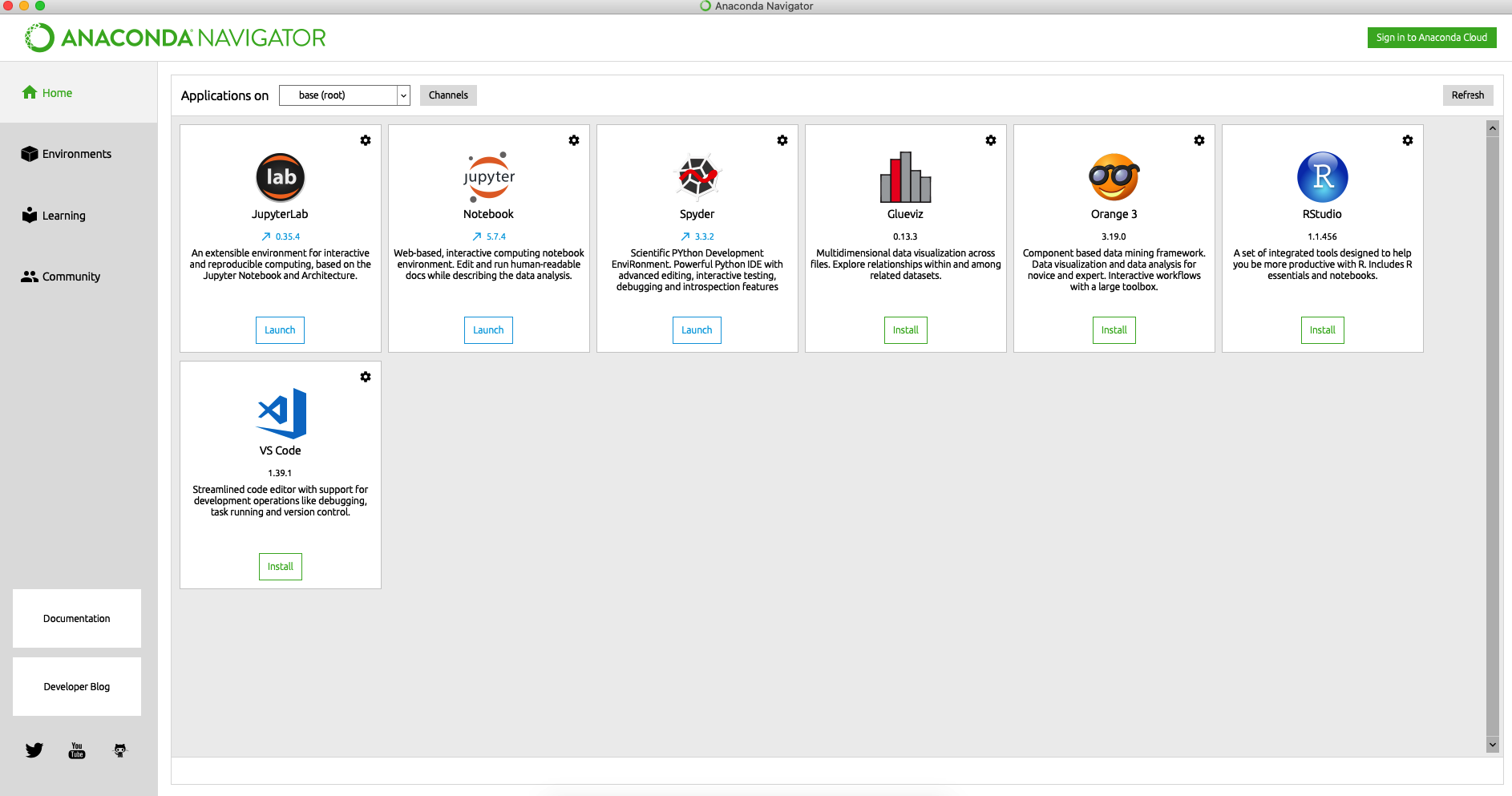
La ejecutamos y luego damos click en "Jupyter Lab"
En nuestro explorador de internet se abrirá esta ventana, es el laboratorio de trabajo de Jupyter
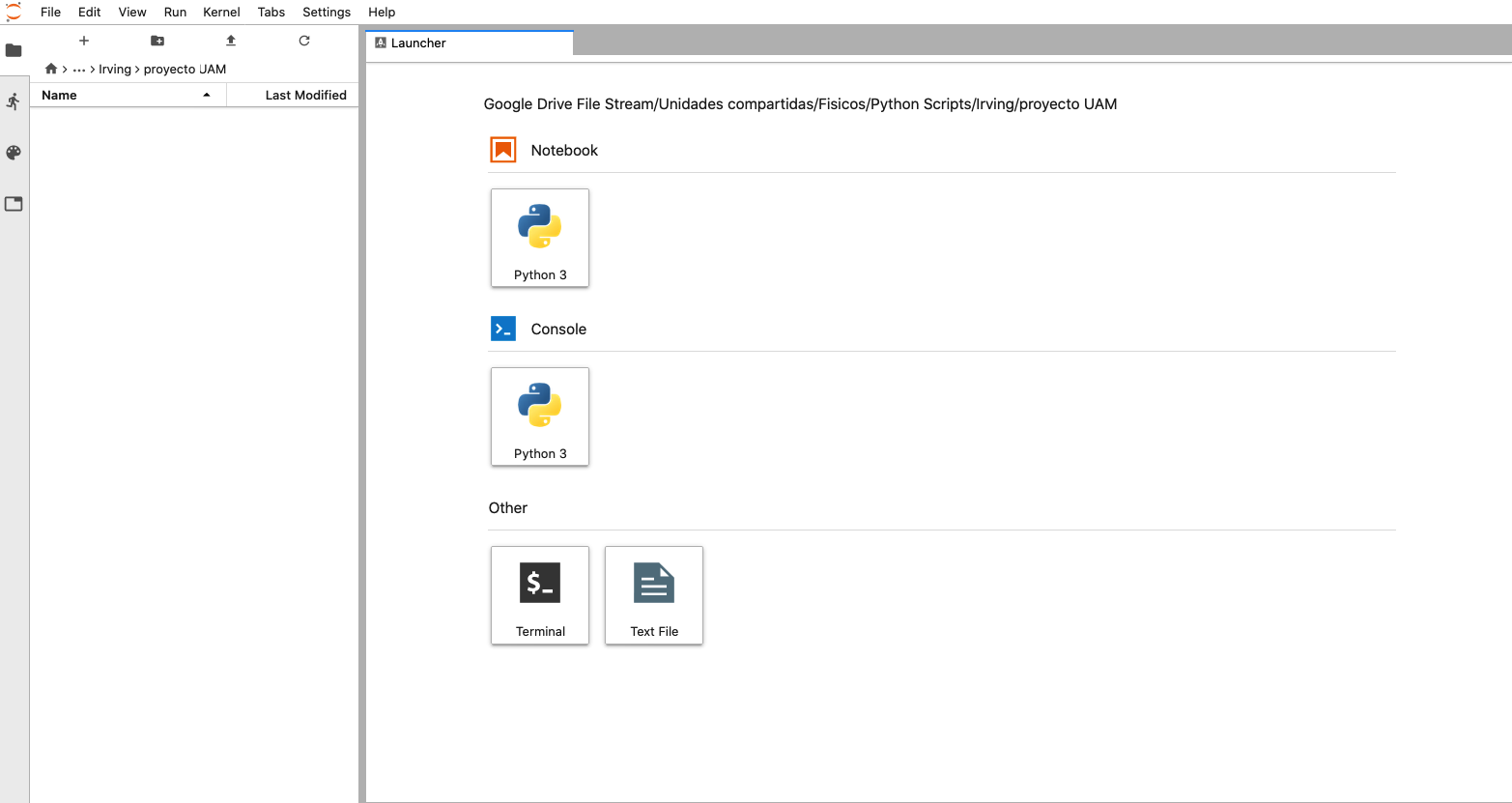
Nuestra principal herramienta para hacer análisis de datos
En el podemos manejar los proyectos de análisis de datos que hagamos. Podemos crear directorios para nuestros proyectos y cuadernos de trabajo
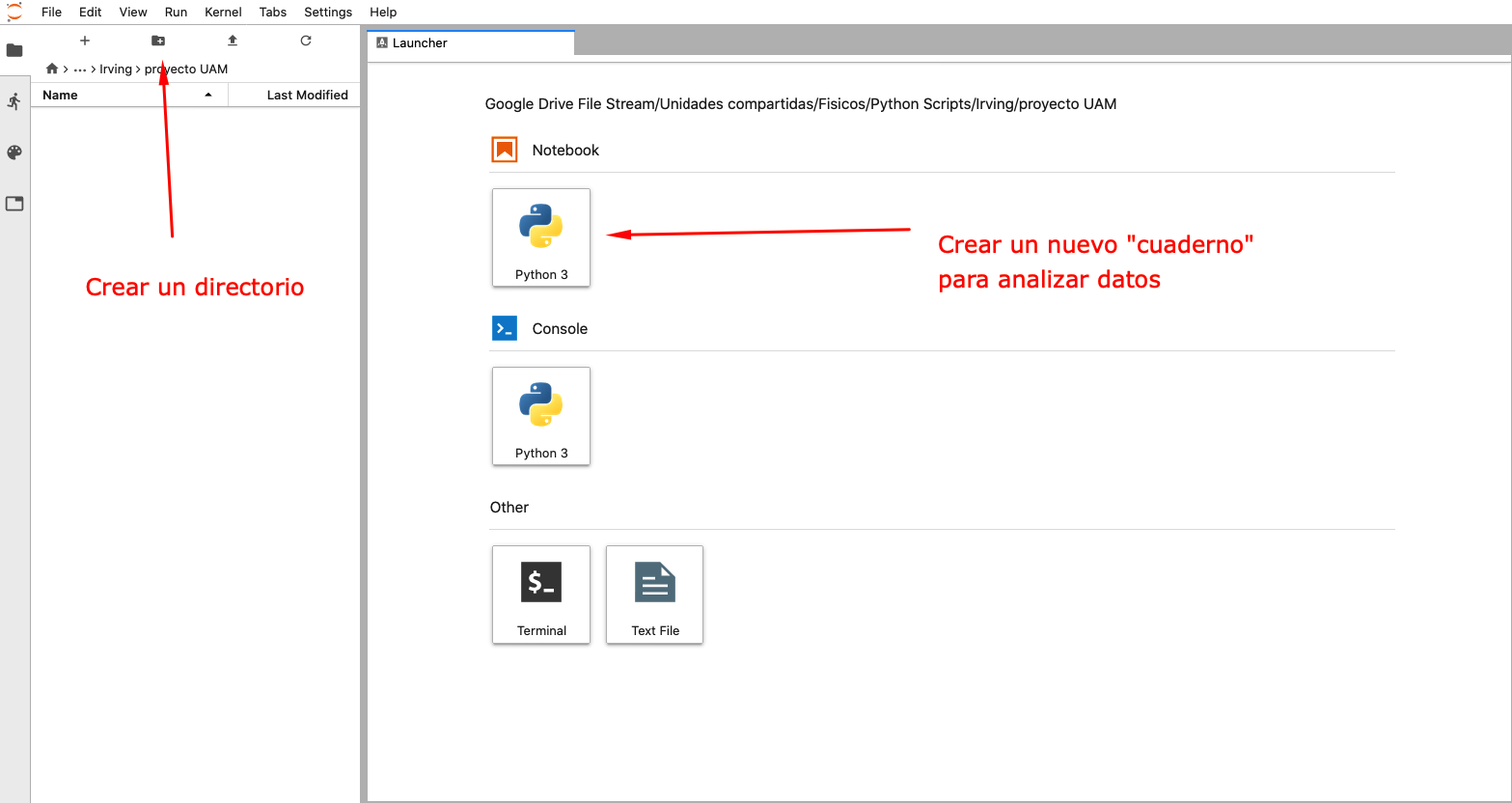
creen un directorio para su proyecto y cambienle el nombre
(pueden sacar un menú con el click derecho sobre el directorio creado)
este directorio también se creó en su computadora, identifiquen donde está y abran la carpeta
Vamos a trabajar con los datos de incidencia delictiva a nivel estatal, los pueden descargar aquí
descargamos el archivo "Cifras de incidencia delictiva estatal"
El primer paso es "ver" el archivo. Podemos usar cualquier hoja de cálculo para abrirlo
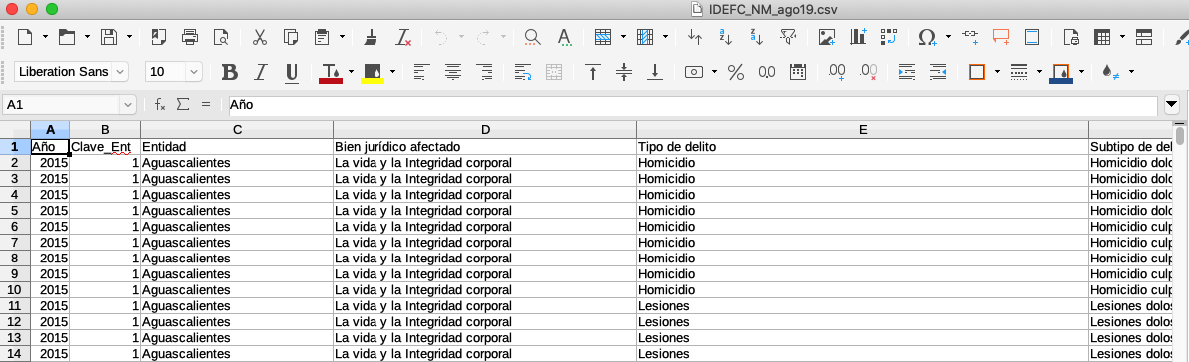
Necesitamos explorar visualmente la estructura de los datos y entender que muestra
- ¿Que datos presenta? ¿Que son los valores?
- ¿Que estructura tienen los datos?
- ¿Que temporalidad?
- ¿A que lugares espaciales hace referencia?
- ¿Cuales son los posibles sesgos y errores?
Si su archivo es un archivo de excel, xlsx, pueden abrirlo en su hoja de cálculo y guardarlo/exportarlo como un archivo de tipo csv (valores separados por comas)
para analizar nuestros datos necesitamos tenerlos cerca
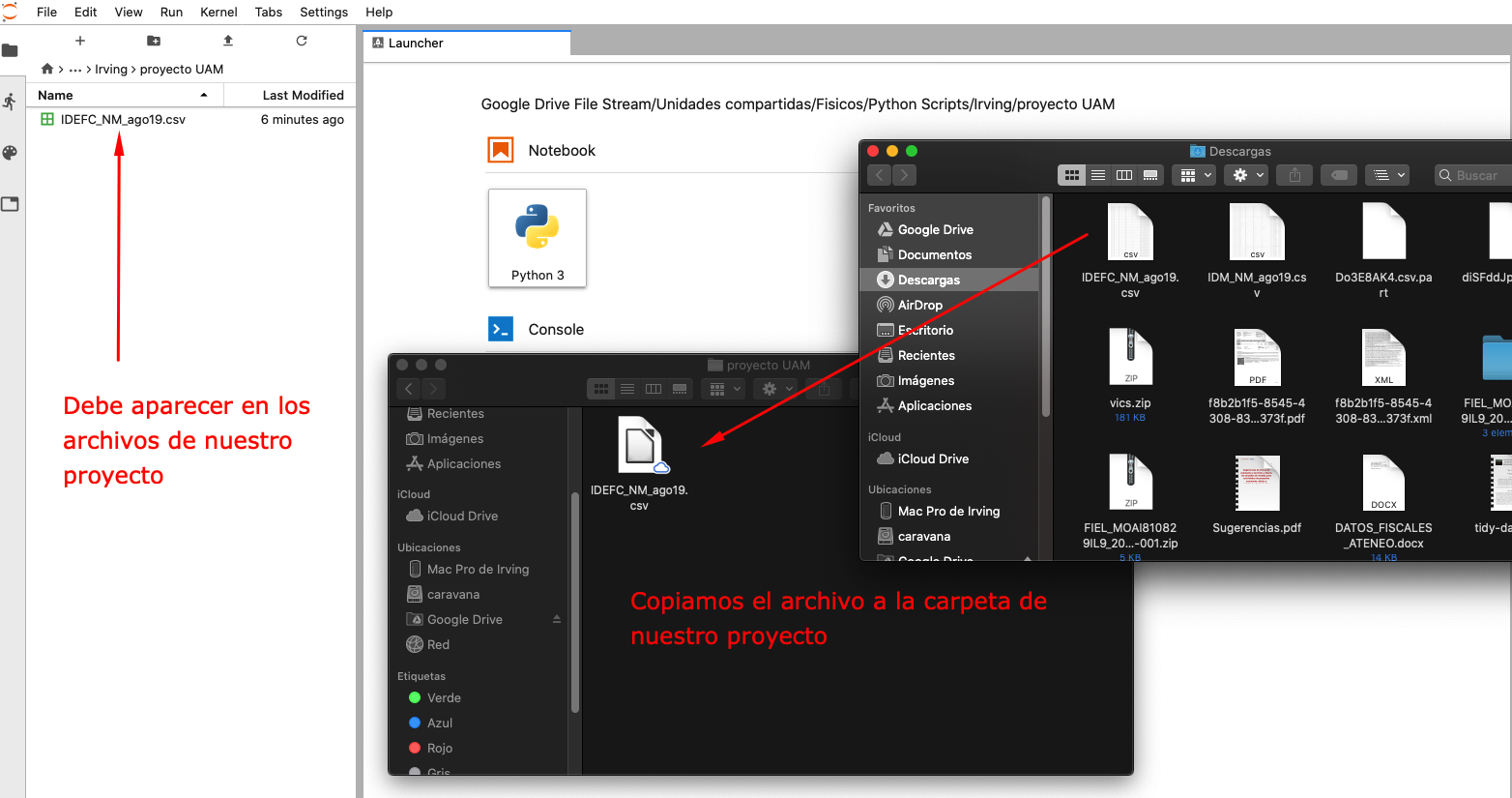
busquen en su computadora la carpeta que crearon para el proyecto y copienlo ahí
abrimos un nuevo "cuaderno" de trabajo
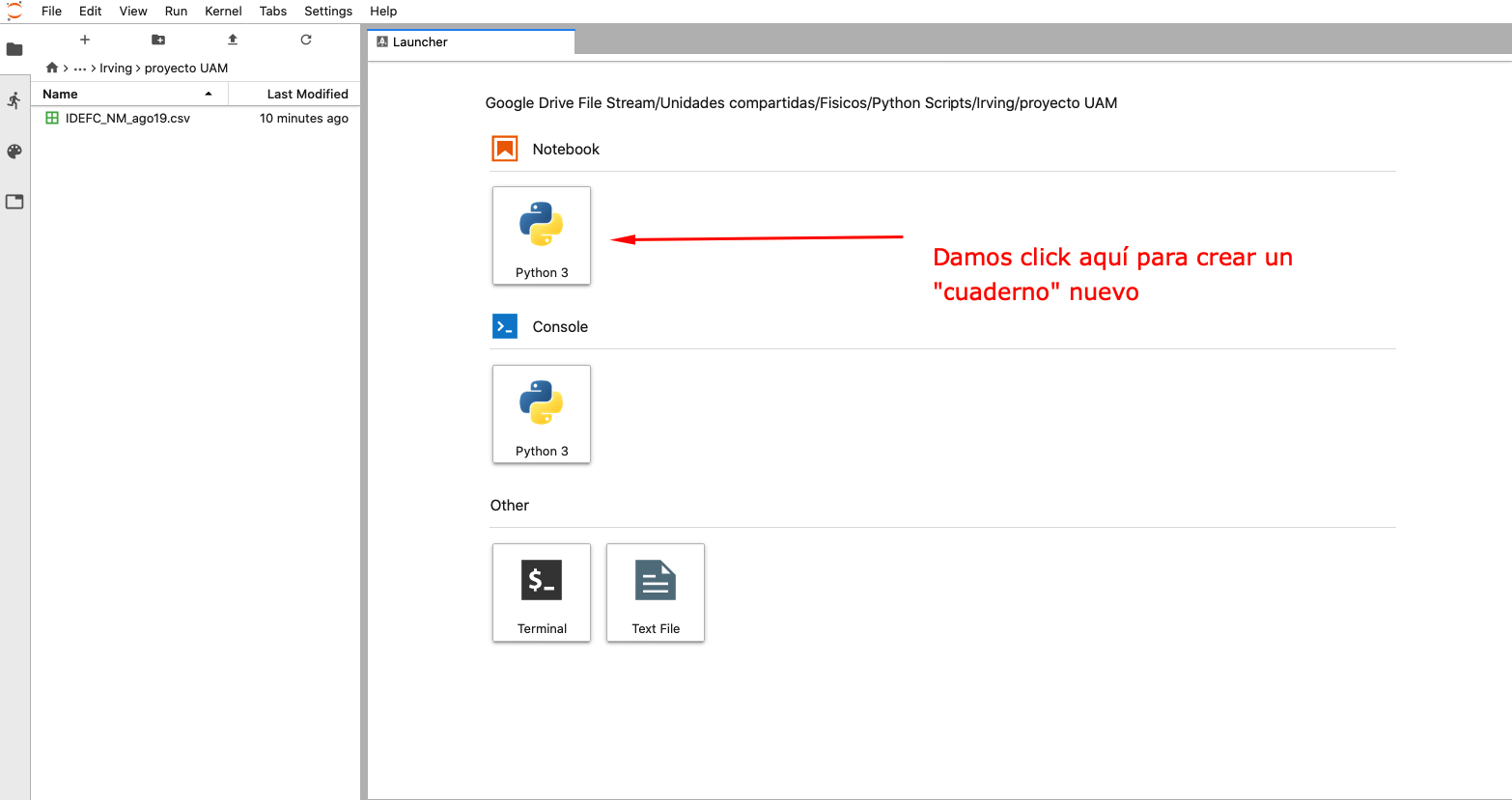
Este cuaderno contiene celdas
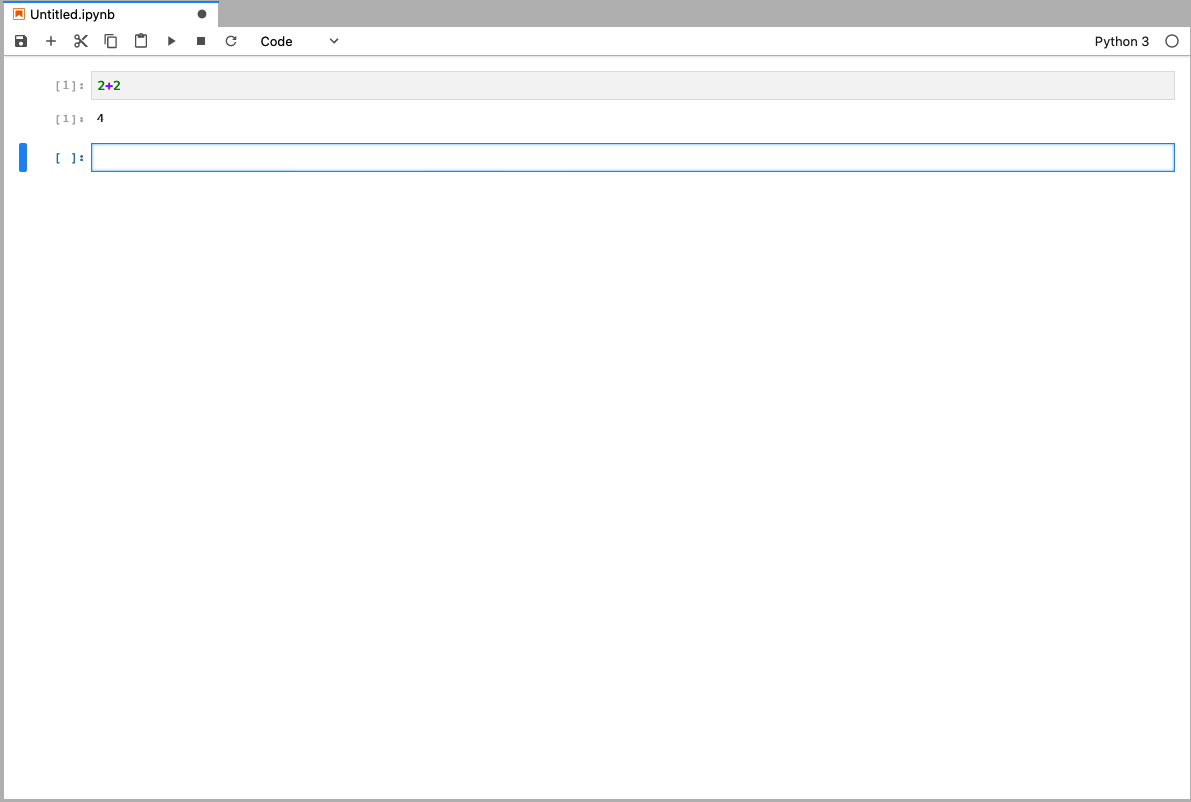
En esas celdas iremos poniendo código y ejecutandolo
Para ejecutar el código de una celda, presionamos "Shift + enter"
Celda a celda iremos construyendo nuestro análisis. Despues de escribir el código en una celda presionamos "Shift + enter" para ejecutarla
Lo que haremos es escribir un pedazo de código en una celda, ejecutarlo y ver el resultado, pasar a la siguiente celda para escribir el paso siguiente del análisis, ejecutarlo, pasar a la siguiente celda y así...
El código de cada celda y los resultados obtenidos podemos irlos guardando en memoria a través de variables y continuar usandolos en celdas porsteriores
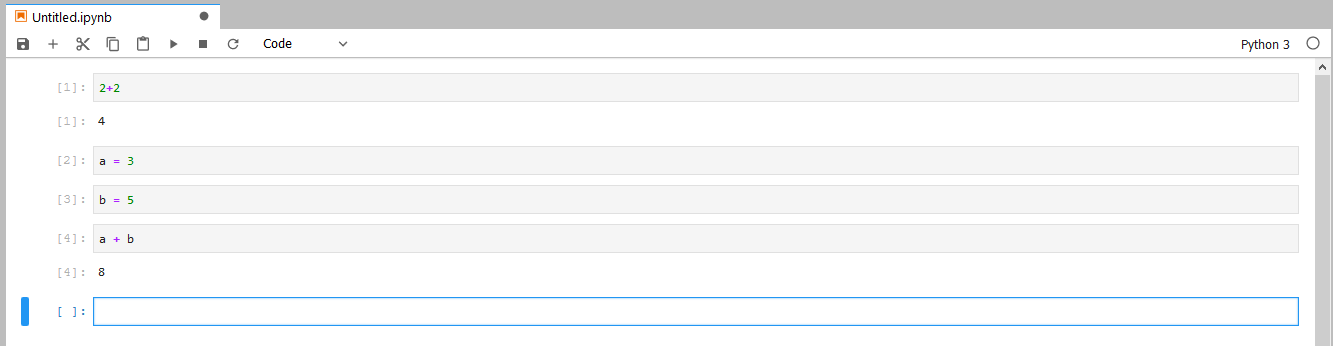
En el ejemplo la variable a y la variable b guardan valores y podemos usarlos despues, para sumarlos
En estas variables podemos guardar diferentes tipos de información:
- Números
- Texto o cadenas
- Listas de números
- Estructuras de datos más complejas (que no usaremos en este tutorial, quizá en alguno futuro), como diccionarios, funciones, objetos, etc.
Muy bien, comencemos el análisis de nuestra base de datos
Todo el código que aparezca a partir de aquí tienes que escribirlo, celda por celda.
Recuerda, después de escribir el código de una celda presiona "Shift + enter" para ejecutarla
Si no la ejecutas es como si no existiera en tu análisis
Python es un lenguaje completo de programación, permite hacer muchas cosas, desde analizar datos hasta controlar robots
Para analizar datos usaremos una librería llamada PANDAS (viene incluida en anaconda)

Necesitamos cargar la librería pandas y cargar nuestros datos. Los guardaremos en una variable llamada "data"
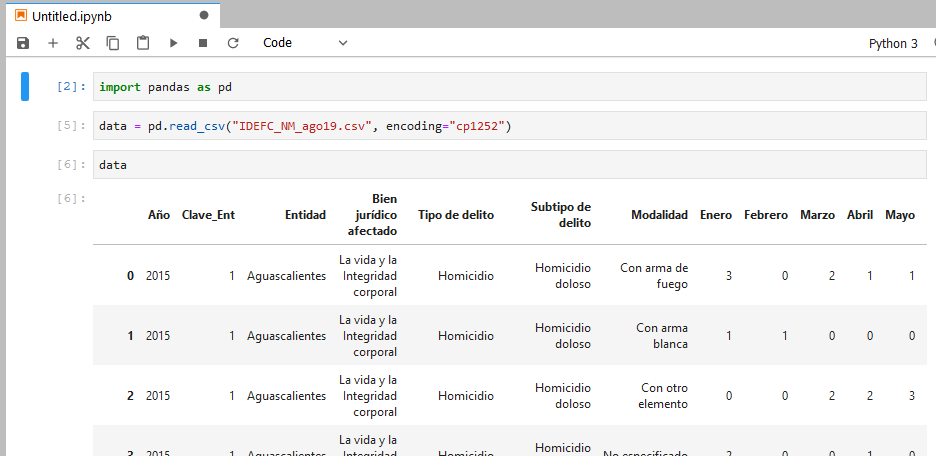
(recuerda, escribes el código de una celda, presionas Shift + Enter para ejecutarlo y luego sigues con la celda siguiente)
La estructura de datos que se generó es un "DataFrame"
Es como una tabla de excel pero lista para ser procesada por código.
Cada valor está identificado por un índice (fila) y un nombre de columna
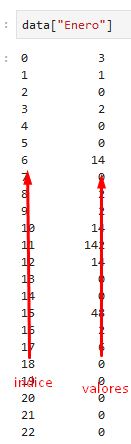
Sobre estas columnas podemos hacer operaciones, por ejemplo sumemos todos los valores de la columna "Enero".
Necesitamos seleccionar toda la columna y luego aplicar la función sum()
para seleccionar utilizamos la notación siguiente: datos["columna"]
en este caso tendríamos que usar:
data["Enero"]
(las comillas son importantes)
Esto genera una "Serie"
La Serie es como un DataFrame de una sola columna
cada valor es identificado por el mismo índice que tenía en el DataFrame
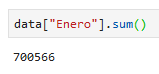
para sumar esta serie tenemos que aplicar la función sum()
se aplica de la siguiente manera:
data["Enero"].sum()
de una serie podemos obtener cosas más interesantes, por ejemplo, una descripción estadística de los valores:
data["Enero"].describe()
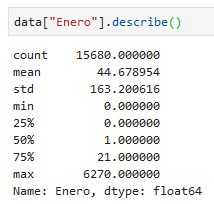
- count: Muestra el número de registros
- mean: muestra el promedio de los valores
- std: muestra la desviación estandard
- min: muestra el valor mínimo
- max: muestra el valor máximo
los demás valores representan al valor que separa a los datos en 25, 50 y 75 por ciento si se ordenaran de menor a mayor (cuartiles)
- 25%: muestra el valor hasta donde llega el primer cuartil
- 50%: muestra el valor hasta donde llega el segundo cuartil (mediana)
- 75%: muestra el valor hasta donde llega el tercer cuartil
todos estos valores representan como se distribuyen los datos:
- ¿Cuántos valores son?
- ¿En donde se acumulan?
- ¿De dónde a dónde van?
- La mayoría, ¿son valores altos o bajos?
Son conceptos relacionados con "el centro" y "la dispersión"
Analizar datos es comparar grupos de valores
En vez del nombre de la columna utilizo una lista de nombres:
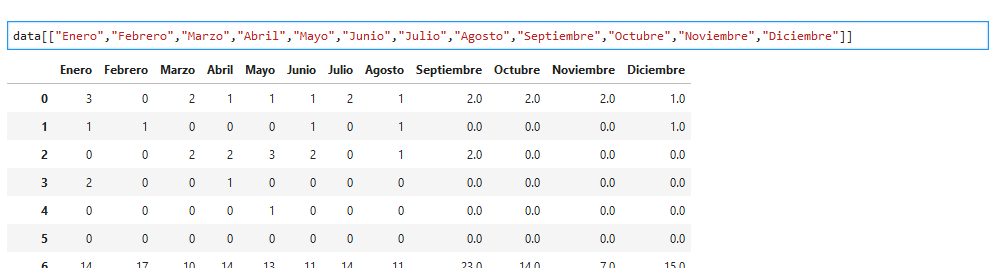
(Noten los dobles corchetes, son importantes)
puedo sumarlas:
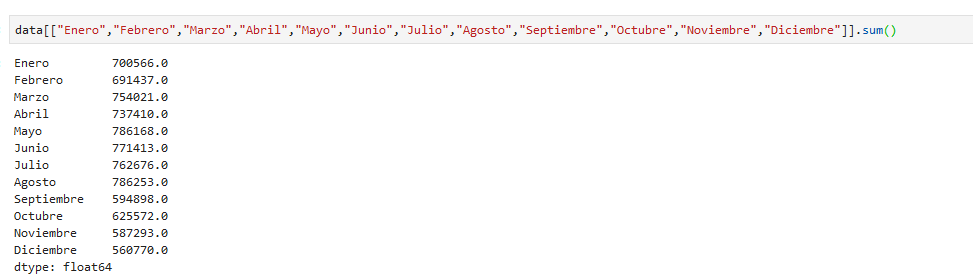
noten que el resultado es una serie, donde los nombres de las columnas utilizadas ahora son el índice
ó puedo describirlas estadísticamente:
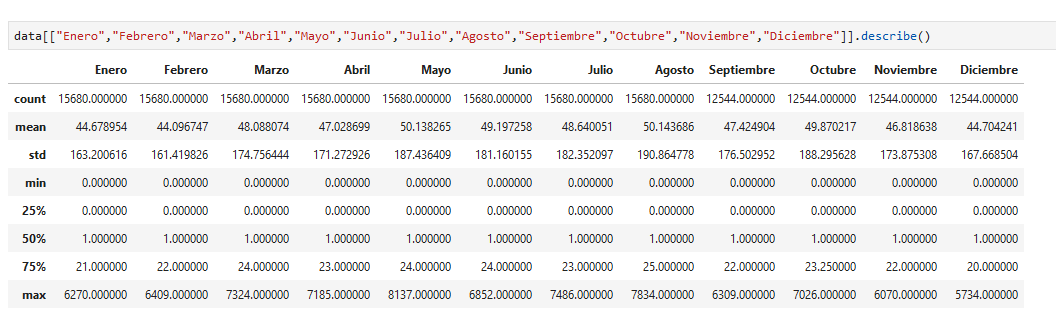
noten que el resultado es una DataFrame, donde los nombres de los resultados ahora son el índice
Ahora si podemos comparar
¿Que información obtenemos?
¿Que estamos analizando?
Las carpetas de investigación que se reportan cada mes en todos los estados, de todos los tipos de delitos, de 2015 a agosto de 2019
Necesitamos filtrar!
Analizar datos es filtrar
podemos filtrar los valores de diferentes categorías
- Año
- Entidad
- Bien jurídico afectado
- Tipo de delito
- Subtipo de delito
- Modalidad
para filtrar necesitamos decir que elementos queremos y cuales no
tomemos como ejemplo la categoría "Modalidad"
data["Modalidad"]
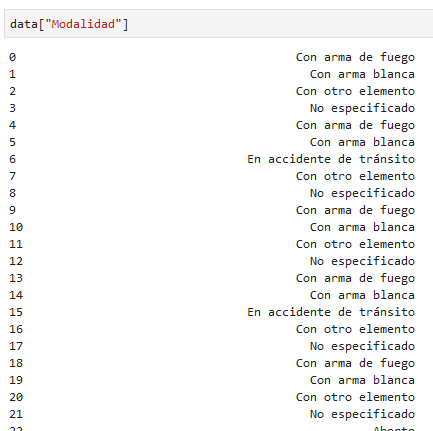
supongamos que queremos todos los elementos que son igual a "Con arma blanca"
esto lo conseguimos usando el simbolo "==" :
data["Modalidad"]=="Con arma blanca"
data["Modalidad"]=="Con arma blanca"

se generó una Serie de "verdaderos" y "falsos", "verdadero" para entradas donde el valor correspnde con "Con arma blanca" y falso para todos los demas
a esta serie la llamaremos condición y la usaremos para filtrar nuestro DataFrame!
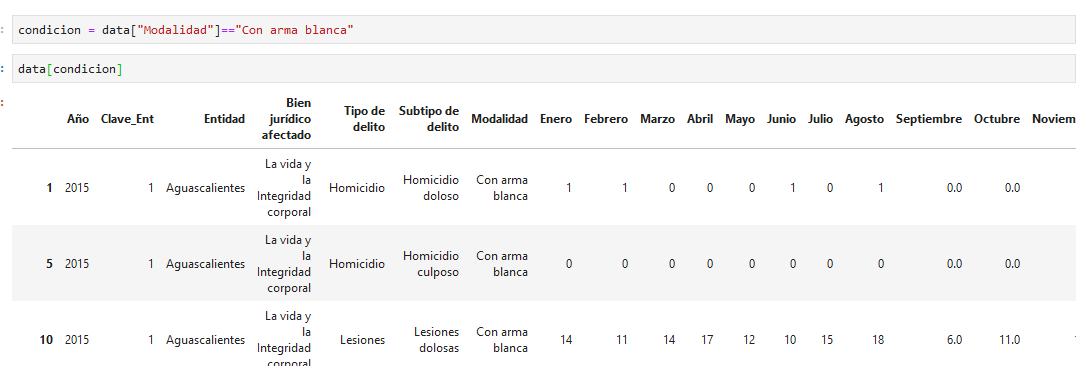
noten como ahora solo tenemos valores con "Modalidad" == "Con arma blanca"
también noten la falta de comillas en condicion, esta es una variable, no un texto
hagamos un filtro más complejo!
Para crear condiciones más complejas usaremos operadores lógicos
- &, "and", "y"
- |, "or", "o"
también podemos usar comparaciones diferentes a la igualdad, por ejemplo menor que < o mayor que >
filtremos todos los homicidios dolosos sucedidos en 2019 con arma de fuego
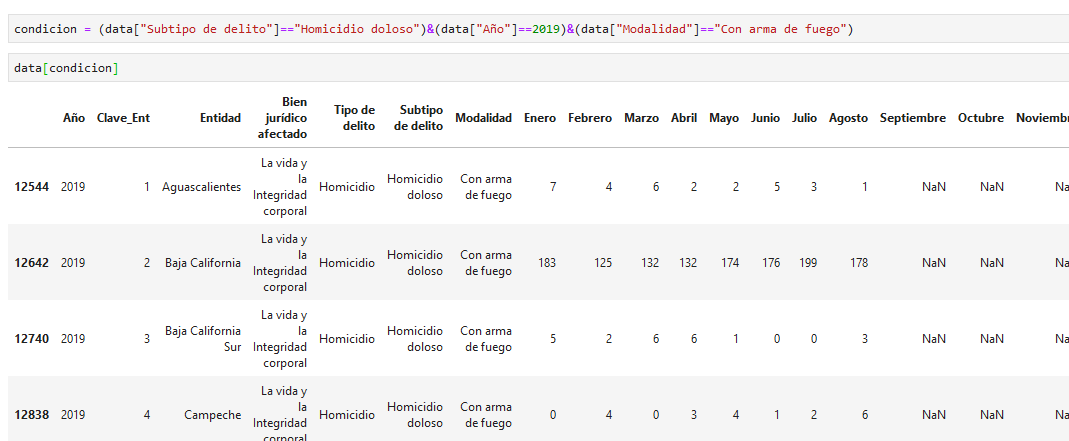
noten como 2019 no tiene comillas porque es un número, no un texto. Cuidado, a veces podría ser un texto (cuando mezclamos numeros con texto)
obtuvimos 32 registros, uno por cada estado, además noten que a partir de septiembre no existen valores (por eso es importante no rellenar con ceros)
esta versión filtrada de los datos la podemos guardar en otra variable, por ejemplo "datos_filtrados"
(los nombres de las variables no pueden contener espacios, en algún momento haré un tutorial de python básico ;-) )

datos_filtrados es un DataFrame que contiene solamente los datos que pasaron nuestro filtro, podemos operar con el como lo hicimos con data
¿Cuántos homicidios dolosos hubo en cada estado en Enero?
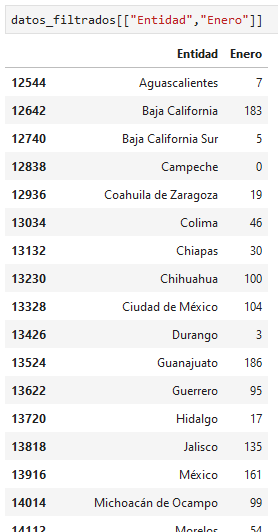
noten como el índice se mantiene del dataFrame anterior
podemos definir un nuevo índice, uno que tenga sentido, los nombres de los estados
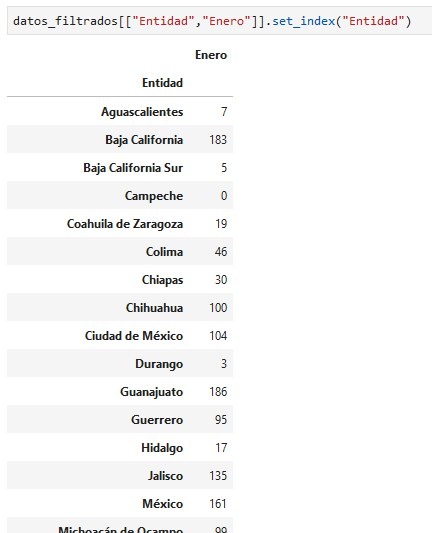
podemos ordenarlos
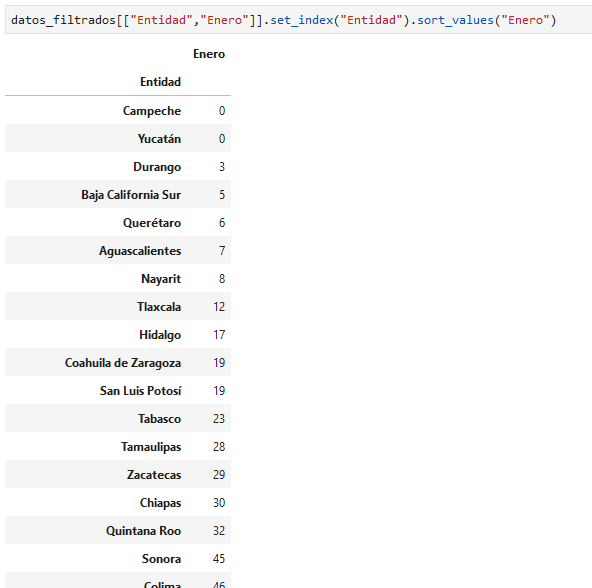
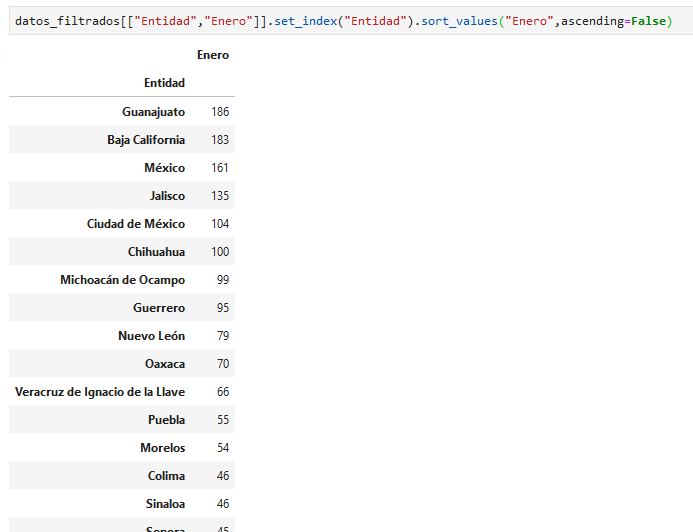
podemos ordenarlos de mayor a menor
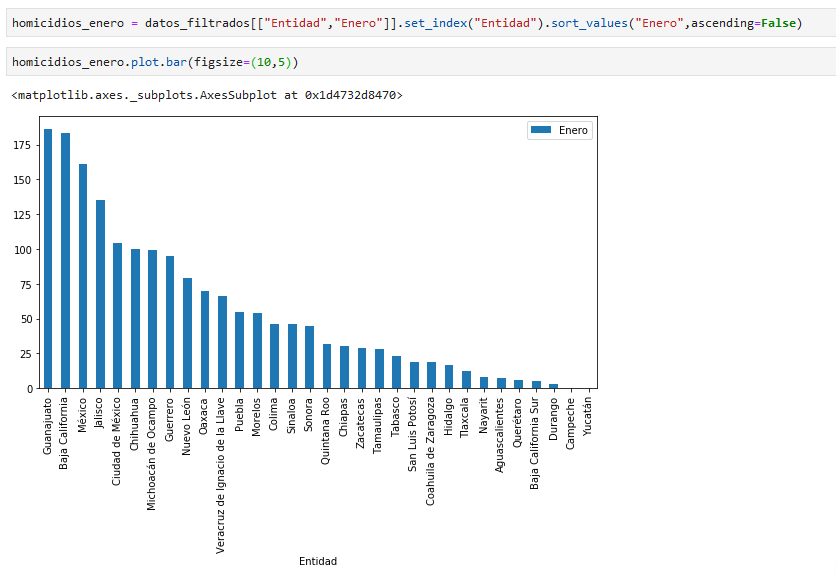
guardemos este dataFrame ordenado en otra variable, homicidios_enero, y grafiquemoslo!
¿Y si quisieramos todos los meses?
podemos pedir todas las columnas que necesitamos, entidad y los meses:
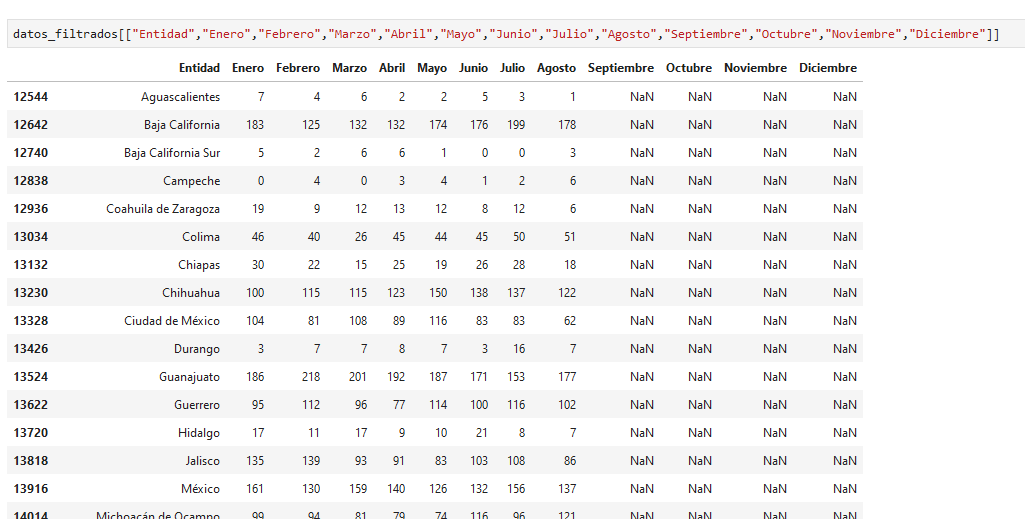
arreglemos el índice y guardemos en la variable homicidios_19
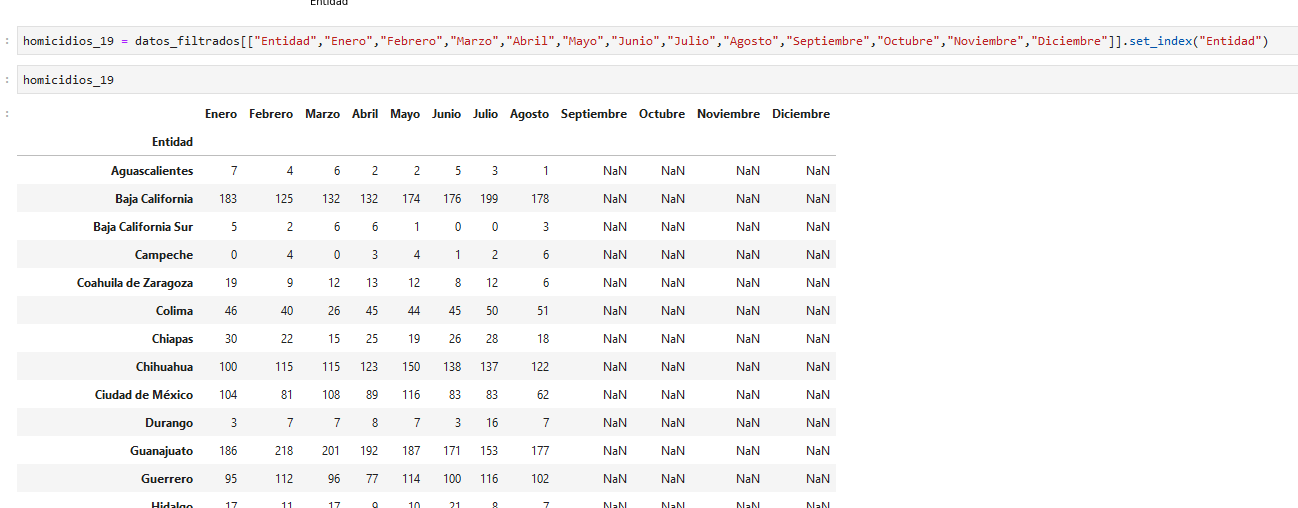
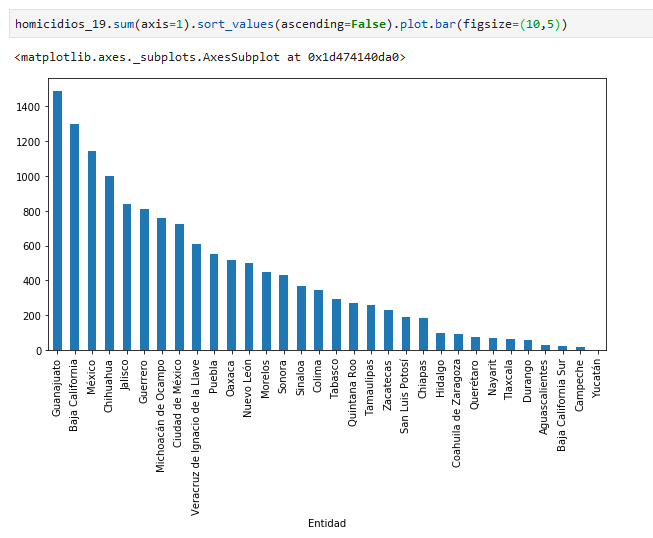
y ahora sumemos para obtener por estado los homicidios de todo 2019:
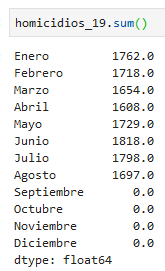
esta suma no nos sirve porque sumamos para los valores de las columnas (axis 0)
(Nos sirve si queremos los homicidios de todo el país por mes)
para poder sumar correctamente necesitamos sumar sobre las filas (axis 1):
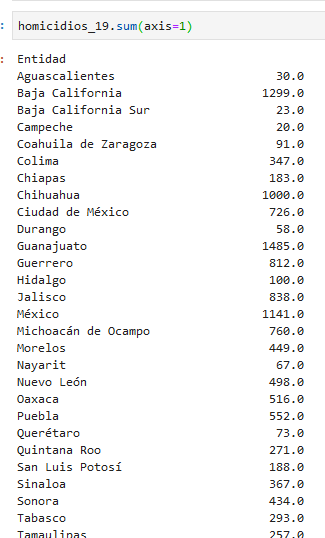
por supuesto podemos ordenar de mayor a menor
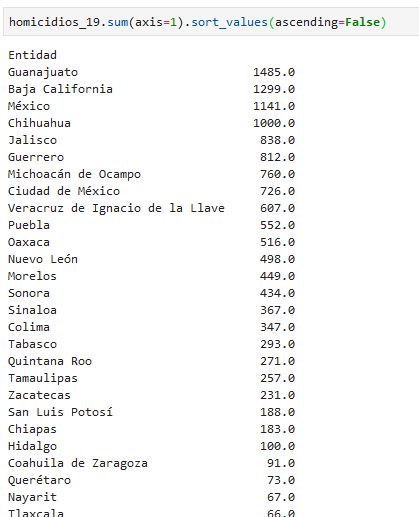
y graficar...
ó guardar los datos filtrados en un archivo nuevo...

Como mencionamos anteriormente esta comparación es injusta, necesitaríamos dividir cada valor por la población del estado para tasar y entonces poder comprarar
Dado que nuestra base de datos no contiene información de población tendríamos que obtenerla de otra base de datos. Esto es un buen ejercicio que dejaremos pendiente para que puedan pensar como hacerlo.
En tutoriales futuros aprenderemos a hacerlo.
PANDAS es muy poderoso, esto solo es la punta del iceberg, pero con esto tienen suficiente para arrancar y hacer grandes análisis de datos.
cualquier pregunta escribanme en twitter: @moaimx
este tutorial lo encuentran en: www.morlan.mx/analisis_datos